AUTOMASKINLÆRING, MOT MODELL AUTOMATISERING
En matematisk modell er på en måte en forenkling av virkeligheten som utnytter informasjonen som er tilgjengelig for å systematisere beslutningstaking. Denne forenklingen gjør at hypoteser om oppførselen til både variabler og systemer kan evalueres gjennom deres oppsummerende representasjon under et sett med postulater, vanligvis basert på data og anvendelse av slutningskriterier. Hovedformålet er å forklare, analysere eller forutsi oppførselen til en variabel.
Auto Machine Learning
Den nåværende revolusjonen innen modelleringsteknikker, kombinert med økt datakraft og mer tilgjengelig og større datalagringskapasitet, har radikalt endret måten modeller har blitt bygget på de siste årene. Denne revolusjonen har vært en nøkkelfaktor som har stimulert bruken av disse nye teknikkene ikke bare i beslutningsprosesser der tradisjonelle tilnærminger ble brukt, men også på områder hvor bruk av modeller ikke var så vanlig. Til slutt, i enkelte bransjer, som finanssektoren, har også bruken av modeller vært drevet av regulering. Standarder som IFRS 9 og 13 eller Basel II har fremmet bruken av interne modeller med sikte på å legge til sensitivitet og gjøre beregningen av regnskapsmessig verdifall eller finansiell risiko mer sofistikert.
Selv om det kan se annerledes ut, har ikke de vanligste modelleringsteknikkene som for tiden brukes i forretningsfeltet en nyere opprinnelse. Nærmere bestemt stammer lineære og logistiske regresjoner fra 1800-tallet. Imidlertid har det i en tid nå vært betydelig utvikling innen nye algoritmer som, selv om de er rettet mot å forbedre hvordan mønstre indentifiseres i dataene, også introduserer nye utfordringer som behovet for forbedrede tolkningsteknikker. Bruken av disse nye matematiske modellene i databehandling er en vitenskapelig disiplin kjent som maskinlæring, siden den lar systemer lære og finne mønstre uten å være eksplisitt programmert til å gjøre det.
Det er flere definisjoner av maskinlæring, to av de mest illustrerende er Arthur Samuel og Tom Mitchell. For Arthur Samuel er maskinlæring " the field of study that gives computers the ability to learn without being explicitly programmed ", mens for Tom Mitchell er det " a program that learns from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks T, as measured by P, improves with experience E”. Disse to definisjonene er vanligvis relatert til henholdsvis uovervåket og overvåket læring.
Som en konsekvens har appetitten til å forstå og trekke konklusjoner fra data økt drastisk. Men samtidig har implementering av disse metodene krevd å endre flere aspekter i organisasjonen og er i sin tur en kilde til potensiell risiko på grunn av utviklings- eller implementeringsfeil eller upassende bruk.
Avansert modellering forbedrer forretnings- og driftsprosesser, eller til og med letter fremveksten av nye forretningsmodeller. Et eksempel kan finnes i finanssektoren, hvor nye digitaliseringsmetoder modifiserer dagens verdiforslag, men også legger til nye tjenester. Ifølge en undersøkelse utført av Bank of England og Financial Conduct Authority på nesten 300 selskaper i finans- og forsikringssektoren, brukte to tredjedeler av deltakerne maskinlæring i prosessene sine. Maskinlæringsteknikker brukes ofte i typiske kontrolloppgaver, som forebygging av hvitvasking (AML) eller svindeldeteksjon, analyse av cybersikkerhetsrelaterte trusler og i forretningsprosesser som kundeklassifisering, anbefalingssystemer eller kundeservice gjennom bruk av chatbots. De brukes også i kredittrisikostyring, prising, drift og forsikringsgaranti.
Andre sektorer har sett et lignende utviklingsnivå. Bruken av maskinlæringsmodeller er vanlig i bransjer som produksjon, transport, medisin, rettsvesen eller detaljhandel og forbruksvarer. Dette har ført til at investeringene i selskaper dedikert til kunstig intelligens har økt fra totalt 1,3 milliarder dollar i 2010 til 40,4 milliarder dollar i 2018. Den forventede avkastningen rettferdiggjør denne investeringen: 63 % av selskapene som har tatt i bruk Machine Learning-modeller har rapportert økte inntekter, med ca. halvparten av dem rapporterer en økning på over 6 %. På samme måte rapporterte 44 % av selskapene kostnadsbesparelser, med omtrent halvparten av dem som oppnådde besparelser over 10 %.
Av de forskjellige endringene organisasjoner gjør for å tilpasse seg dette nye paradigmet, er rekruttering og oppbevaring av talent fortsatt sentralt. Til å begynne med har bedrifter hatt behov for å utvide teamene sine som spesialiserer seg på maskinlæring. Etterspørselen etter fagpersoner i dette feltet økte med 728 % mellom 2010 og 2019 i USA, med en kvalitativ endring i etterspørselen etter generelle data scientist ferdigheter og kunnskap som også var bemerkelsesverdig.
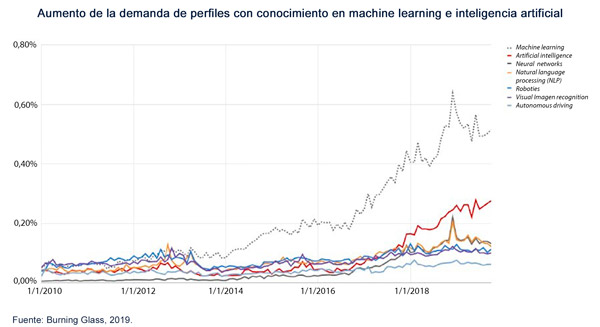
Men slik etterspørselen etter generisk maskinlæring og data scientist ferdigheter er ikke alltid tilfelle: for å analysere de økende datamengdene som er tilgjengelige ved å bruke stadig mer sofistikerte verktøy, har krav til ferdigheter blitt mer spesifikke for å inkludere kunnskap om forskjellige programmeringsspråk som f.eks. Python, R, Scala eller Ruby, evnen til å håndtere databaser i big data-arkitekturer, kunnskap om cloud computing, avansert matematisk og statistisk kunnskap, og spesialisert etterutdanning. Følgelig har mange forskjellige jobber i markedet blitt vanskelige å fylle på grunn av deres høye og spesifikke kompetansekrav. I tillegg betyr hastigheten bedrifter genererer data med at, selv med en stabil tilgang på data scientist, er den nåværende rekrutteringsløsningen ikke skalerbar.
Det er imidlertid ikke bare nødvendig å ha spesialistteam, men også å implementere nye utviklingsprosedyrer, gjennomgå valideringsmetoder, gjennomgå og vurdere modeller på validerings- og revisjonsområdene, og gjøre viktige kulturelle endringer på andre områder for at denne implementeringen skal være effektiv. Bruken av disse nye prosessene skaper en kjedereaksjon som påvirker hele modellens livssyklus, inkludert spesielt identifisering, styring og styring av modellrisiko. Mange av disse modellene krever også tilsynsgodkjenning, som i finansnæringen (f.eks. kapital- eller avsetningsmodeller), eller i farmasøytisk industri, noe som tilfører nye utfordringer som behovet for å sikre tolkbarheten til modellene som brukes, samt å utvikle andre elementer av modelltillit.
Et annet bemerkelsesverdig aspekt ved investeringen i maskinlæringsmetoder er at utviklingen er ujevn på tvers av organisasjoner: behovet for å gjennomgå validerings-, revisjons- og godkjenningsprosesser etablert av forskrifter, eller kravet om å opprettholde spesifikke dokumentasjonsstandarder, skaper forskjeller i implementeringen av interne modeller på tvers av firmaer. I følge EBAs «big data and analytics report» tar finansinstitusjoner i bruk digitale transformasjonsprogrammer eller fremmer bruken av maskinlæringsteknikker på områder som risikoreduksjon (inkludert automatisert scoring, operasjonell risikostyring eller svindel) og Know Your Customer-prosesser. "Although the use of machine learning may represent an opportunity to optimize capital, from a prudential framework perspective it is premature to consider the use of machine learning techniques appropriate for determining capital requirements".
Det er også operasjonelle risikoer som er vanskelige å oppdage, for eksempel de som oppstår fra menneskelige feil under modellimplementering, eller de som er relatert til datalagringssikkerhet, som bør administreres riktig for å sikre at maskinlæringssystemer brukes i et passende miljø. Et eksempel på dette er rammeverket etablert av EU-kommisjonen i disse sakene, som dekker ulike aspekter av modelleringsprosessen. Til slutt,må modeller fungere pålitelig og brukes etisk slik at de kan stoles på i beslutningsprosessen. EBAs forslag i denne forbindelse, basert på syv pilarer av tillit, er av spesiell interesse: etikk, tolkbarhet, unngåelse av bias, sporbarhet, databeskyttelse og kvalitet, sikkerhet og forbrukerbeskyttelse. Disse problemene har også blitt identifisert som sentrale elementer av universiteter og næringsliv.
I denne sammenheng krever ulike modellutviklingsoppgaver svært forskjellige tider: oppgavene før og komplementære til analyse krever også mye tid og ressurser for å forberede, rense og generelt behandle dataene; 60 % av en data scientists tid går med til å rense data og organisere informasjon, mens 9 % og 4 % av tiden deres brukes på henholdsvis knowledge discovery tasks og algorithm tuning. Alt dette driver behovet for å endre måten modellutvikling, validering og implementering tilnærmes på, for å dra nytte av de nye teknikkene samtidig som man løser vanskelighetene knyttet til bruken av dem, samt reduserer eventuelle potensielle risikoer.
Av de grunnene som er skissert ovenfor, er det en klar trend mot å automatisere prosesser knyttet til bruk av avanserte analyseteknikker – generelt kalt automatisert maskinlæring eller AutoML, hvor målet ikke bare er å automatisere de oppgavene der heuristiske prosesser er begrenset og lett automatiserte, men også for å gjøre det mulig å generere mer automatiserte, ordnede og sporbare algoritme- og pattern search prosesser. Ifølge Gartner vil mer enn 50 % av data science oppgaver være automatisert innen 2025.
Videre tilbyr denne trenden mot automatisering en rekke muligheter, for eksempel de som tilbys av automation systems architecture som f.eks workflow design, model inventory, eller komponentvalidering. Automatiserte maskinlæringssystemer integrerer ulike verktøy for å utvikle modeller, og reduserer også kostnader, utviklingstid og systemimplementeringsfeil.
AutoML-systemer og -metoder søker blant annet å:
- redusere tiden data scientists bruker på å utvikle modeller gjennom bruk av maskinlæringsteknikker, og la fagpersoner uten data science bakgrunn utvikle maskinlæringsalgoritmer;
- forbedre modellytelse, samt modellsporbarhet og sammenlignbarhet mot manuelle hyperparameter search techniques r;
- utfordringsmodeller utviklet ved bruk av andre tilnærminger;
- utnytte investeringene som er gjort i form av både tid og ressurser for å utvikle koder og forbedre systemets komponenter effektivt og med større sporbarhet;
- og forenkle valideringen av modeller og lette planleggingen av dem.
Med dette i betraktning har dette dokumentet som mål å beskrive nøkkelelementene i AutoML-systemer. For dette formålet er det strukturert i tre seksjoner, med tre mål:
- I den første delen analyseres faktorene som forklarer utviklingen mot automatisering av maskinlæringsprosesser, og årsakene til utviklingen av AutoML-systemer, både gjennom componentization og automatisering.
- Den andre delen gir et beskrivende syn på de viktigste AutoML-rammeverkene, og forklarer hvilke tilnærminger som følges, både i det akademiske feltet og i praktiske erfaringer rettet mot å automatisere modelleringsprosesser gjennom maskinlæringsteknikker.
- Til slutt har den tredje delen som mål å illustrere resultatene av AutoML-systemutvikling, og presentere en cas konkurranse arrangert av Management Solutions tidlig i 2020. Målet med denne konkurransen, rettet mot MS-ansatte, var å designe en automatisert maskinlæringsmodell.
For mer informasjon, se hele dokumentet i pdf (også tilgjengelig på spansk ) og portugisisk ) .
Relaterte dokumenter: Machine Learning, a key component in business model transformation | Data science and the transformation of the financial industry | Model Risk Management: Quantitative and qualitative aspects